Competitive programming problems increasingly serve as valuable benchmarks to evaluate the coding capabilities of large language models (LLMs) due to their complexity and ease of verification. Yet, current coding benchmarks face limitations such as lack of exceptionally challenging problems, insufficient test case coverage, reliance on online platform APIs that limit accessibility. To address these issues, we introduce LiveOIBench, a comprehensive benchmark featuring 403 expert-curated Olympiad-level competitive programming problems, each with an average of 60 expert-designed test cases. The problems are sourced directly from 72 official Informatics Olympiads in different regions conducted between 2023 and 2025.
LiveOIBench distinguishes itself through four key features: (1) meticulously curated high-quality tasks with detailed subtask rubrics and extensive private test cases; (2) direct integration of elite contestant performance data to enable informative comparison against top-performing human; (3) planned continuous, contamination-free updates from newly released Olympiad problems; and (4) a self-contained evaluation system facilitating offline and easy-to-reproduce assessments.
Benchmarking 32 popular general-purpose and reasoning LLMs, we find that GPT-5 achieves a notable 81st percentile, a strong result that nonetheless falls short of top human contestant performance, who usually place above 90th. In contrast, among open-weight reasoning models, GPT-OSS-120B achieves only a 60th percentile, underscoring significant capability disparities from frontier closed models. Detailed analyses indicate that robust reasoning models prioritize precise problem analysis over excessive exploration, suggesting future models should emphasize structured analysis and minimize unnecessary exploration.
Our benchmark consists of 403 coding problems collected directly from the official websites of 72 competitions across 14 renowned Informatics Olympiads, focusing on contests held from 2023 onward. To build this benchmark, we developed custom web crawlers tailored to each official competition website, complemented by thorough manual verification to ensure high accuracy and integrity of the collected data. The dataset includes challenging problems designed by experts, each with clearly defined subtasks that enable precise partial scoring. Additionally, expert-designed private test cases are included to guarantee reliable evaluation. The dataset is further enriched with detailed algorithm tags, clearly marked difficulty levels, and contestant Codeforces ratings, facilitating comprehensive performance analyses. Our benchmark uniquely supports direct comparisons between models and human contestants through percentile rankings, medals, and ratings. To keep the dataset relevant and uncontaminated, we continuously incorporate new contests directly from the official websites of actively maintained competitions.
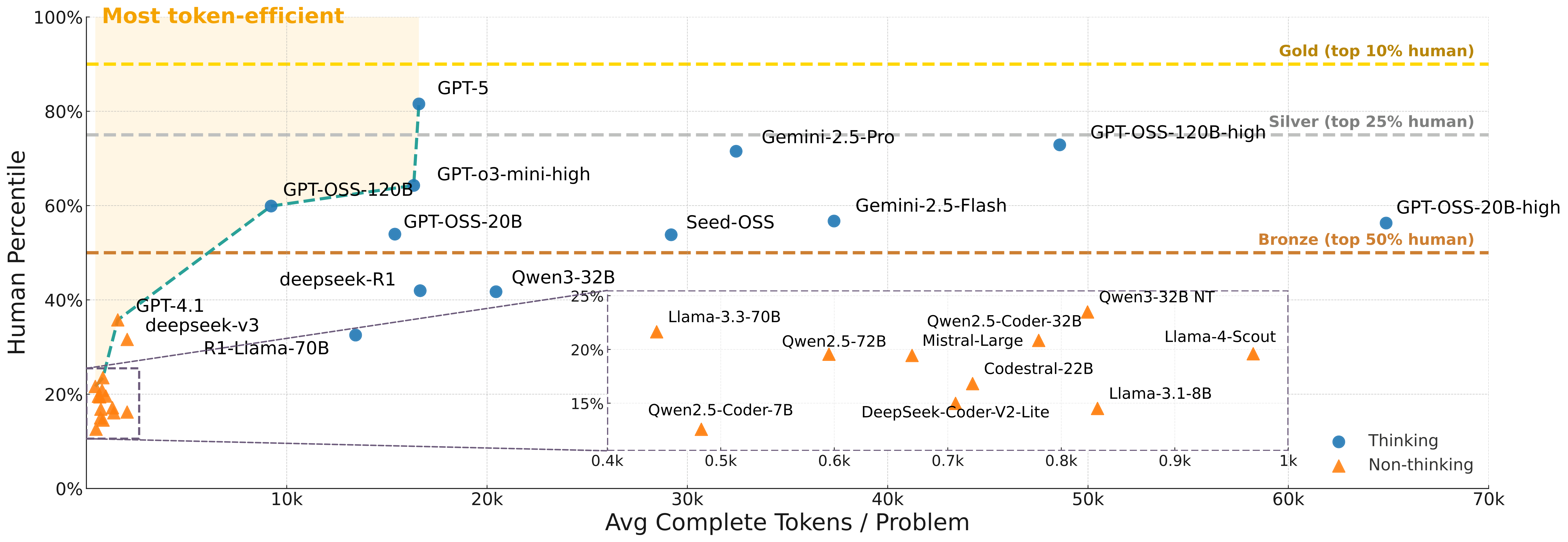
This figure show average human percentile across all contests of each model against completion tokens per problem. Our comprehensive benchmarking of 32 LLMs demonstrates that proprietary models like GPT-5 currently lead in competitive coding performance, achieving exceptional token efficiency and outperforming approximately 82% of human contestants. However, GPT-5 still falls short of top-tier human competitors, highlighting a clear performance gap at the elite level. Open-weight "thinking" models such as GPT-OSS-120B significantly narrow this gap, especially under extended reasoning budgets, while non-thinking models consistently lag, underscoring the critical importance of extended reasoning. Additionally, sequential scaling strategies further enhance smaller models' capabilities, emphasizing inference-time approaches' effectiveness in bridging performance gaps. A multifaceted evaluation approach—including human percentile, medal rankings, and Codeforces ELO—provides deeper insights into these nuanced differences in model proficiency. Full results can be viewed at our leaderboard page.
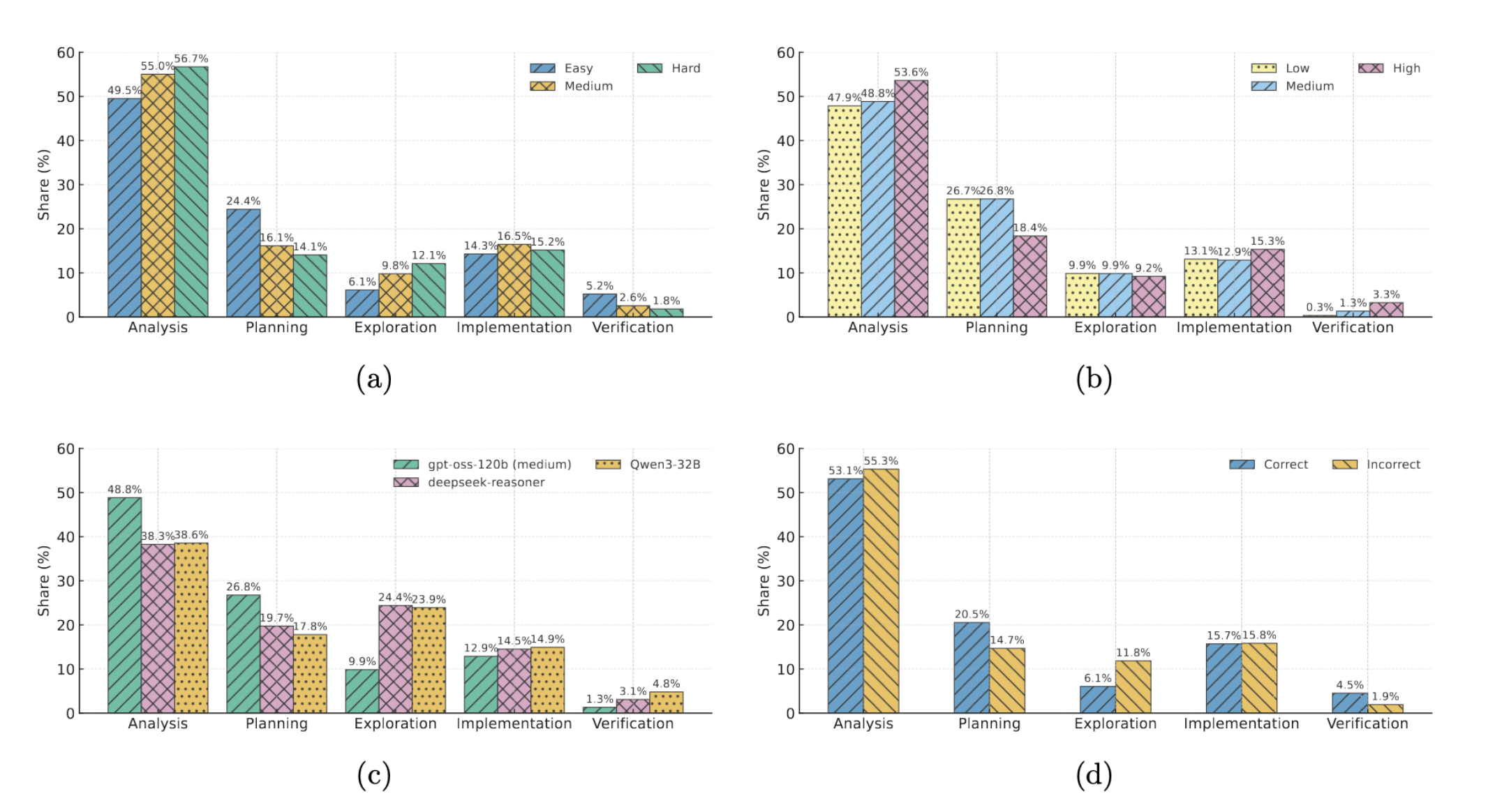
The figure provides an analysis of how reasoning behaviors in LLMs correlate with problem difficulty, reasoning budgets, model capabilities, and solution correctness. As problem difficulty increases (a), GPT-OSS-120B-High prioritizes exploration and deeper analysis, reducing initial planning and verification efforts. Conversely, when reasoning budgets increase (b), the model strategically directs additional resources toward deeper analysis, implementation, and verification without increasing exploration. Stronger reasoning models (c) further demonstrate reduced exploration, allocating more tokens to structured planning, detailed analysis, and solution development. Finally, correct solutions (d) prominently feature structured planning and targeted verification steps, significantly reducing the need for continuous re-analysis and exploration, highlighting the importance of robust initial reasoning frameworks.
@article{zou2025liveoibench,
title={LiveOIBench: Can Large Language Models Outperform Human Contestants in Informatics Olympiads?},
author={Zou, Kaijian and Xiong, Aaron and Zhang, Yunxiang and Zhang, Frederick and Ren, Yueqi and Yang, Jirong and Lee, Ayoung and Bhushan, Shitanshu and Wang, Lu},
journal={arXiv preprint arXiv:2510.09595},
year={2025},
url={https://arxiv.org/abs/2510.09595},
doi={10.48550/arXiv.2510.09595}
}